Bestärkendes Lernen – interaktive Lerneinheit
Übersicht
Bestärkendes Lernen am Beispiel einer interaktiven Simulation
Schlüsselwörter: Machine Learning, KI-Anwendungen
Fächer: Informatik, Mathematik, Naturwissenschaften und Technik
Altersstufe der Schüler*innen: ab 14 Jahre
Zeitrahmen: 2 Doppelstunden
Dieses Material ist für selbstorganisiertes Lernen geeignet. Es besteht aus einer problematisierenden Einführung in das Thema Bestärkendes Lernen, einer Anleitung mit Hintergrundwissen zur Simulation und der eigentlichen interaktiven Simulation am Beispiel einer Goldsuche in einer zweidimensionalen Gitterwelt.
Benötigte Hardware/Software:
- Internetzugang
- PCs/Laptops/Chromebooks/Tablets
Autor: Samuel Richter, mit einer unterrichtspraktischen Einleitung von Daniel Janssen
Die Einheit „Bestärkendes Lernen“ wurde von Samuel Richter entwickelt, der 2024 sein Abitur am Emsland Gymnasium in Rheine absolvierte und als Schüler des Informatik-Leistungskurses der Kooperationsschule Gymnasium Dionysianum das Projekt „Bestärkendes Lernen“ in Form einer besonderen Lernleistung im Rahmen des Abiturs entwickelte. Von der Planung bis zur Umsetzung als interaktive Webanwendung stand für Richter, der nach dem Abitur ein Informatikstudium aufgenommen hat, von Anfang an die Sinnhaftigkeit des Projekts im Vordergrund: eine Anwendung zu schaffen, die nicht zu trivial ist, um als echtes Beispiel für Bestärkendes Lernen zu dienen, aber auch nicht zu komplex, um nicht mehr verstanden zu werden. Da dieses Projekt aus dem Unterricht für den Unterricht entstanden ist, veröffentlichte Richter zusammen mit seinem Informatiklehrer Dr. Daniel Janssen das als kleine Unterrichtssequenz aufbereitete Material bei Science On Stage. Gerade im Hinblick auf den in dieser Zeit neu erarbeiteten Lehrplan für Informatik in der Sekundarstufe I in NRW gewinnt das Thema „Bestärkendes Lernen“ zunehmend an Bedeutung, da es neben dem überwachten und unüberwachten Lernen einen der drei Schwerpunkte markiert, die Einzug in den nordrhein-westfälischen Lehrplan gehalten haben.
© 2023–2025 S. Richter, D. Janssen
Die Nutzung dieses Unterrichtsmaterials ist frei (Creative-Commons-Lizenz CC-BY-SA), der Code des verlinkten interaktiven Elements ist jedoch urheberrechtlich geschützt und keiner freien Lizenz zugeordnet. Die Einsicht in den Code mittels Deobfuskation sowie die Verwendung dieses Codes oder von Auszügen daraus ist nicht gestattet.
Einführung mit Aufgaben: einen Roboter auf einem Spielfeld manuell steuern
Betrachte das abgebildete Spielfeld. Es enthält einen Roboter, der zum Feld mit dem Gold gesteuert werden soll. Dazu kann er nach oben, unten, rechts und links bewegt werden. Er darf jedoch nicht auf einem Feld mit einem Hindernis landen. Um den Roboter zu steuern, benutzt man die Steuerungspfeile.

In dem abgebildeten Beispiel gibt es zwei Möglichkeiten für den besten Weg:


Mit beiden Lösungen steuert man den Roboter vorbei an den Hindernissen zum Ziel. Es wären auch andere Wege, theoretisch unendlich viele Wege denkbar, den Roboter zum Ziel zu manövrieren. Die beiden abgebildeten Wege sind jedoch optimal, da sie jeweils nur fünf Schritte benötigen.
Manuelles Steuern (1)
Betrachte die folgende Situation und überlege dir, welche Schritte des Roboters nötig wären, um ihn zum Ziel zu führen.

Benutze insgesamt fünf Pfeile. Du wirst folgende Pfeile zum Teil mehrfach benötigen: oben, rechts, links.
Der optimale Weg lautet:

Manuelles Steuern (2)
Spielen wir eine weitere Situation durch. Betrachte wiederum die folgende Situation und überlege dir, welche Schritte des Roboters nötig wären, um ihn zum Ziel zu führen.

Benutze insgesamt sechs Pfeile für eine optimale Lösung. Du wirst folgende Pfeile zum Teil mehrfach benötigen: oben, rechts.
Hinweis: Es gibt mehrere Möglichkeiten.
Es gibt vier verschiedene Möglichkeiten mit sechs Pfeilen. Eine Lösung davon ist:

Die weiteren Möglichkeiten sind:

Zwischenfazit zum manuellen Steuern
In allen bisherigen Beispielsituationen, die gezeigt wurden, war es möglich, den Roboter durch Pfeilsteuerung zum Gold zu führen. Allerdings waren alle Wege unterschiedlich, und manchmal gab es sogar gleich gute Lösungsalternativen. Selbst wenn man pro Startsituation nur einen einzigen Weg betrachtet, war allen Beispielen gemeinsam, dass jeweils eine ganz andere, sogar unterschiedlich lange Kombination von Pfeilen zum Ziel führte. Und diese Kombination von Pfeilen hing einzig und allein vom Startpunkt des Roboters ab.
Wenn man sich klarmacht, dass der Roboter einzig mit den Pfeilen für die vier Richtungen gesteuert werden kann und ansonsten nur einen Sensor für Hindernis unter mir (verloren) und Gold unter mir (gewonnen) hat, dann merkt man schnell, dass der Roboter gar keinen Weitblick hat, wie wir es haben, wenn wir das Spielfeld betrachten. Einem Menschen, der von außen auf das Spielfeld blickt, ist sofort klar, wohin der Roboter gehen muss. Dem Roboter selbst ist dies jedoch nicht klar. Er muss sich Feld für Feld bewegen oder von außen z. B. durch Programmierung bewegt werden – und dazu gibt es nur die vier Pfeilrichtungen, die ihn lediglich auf sein Nachbarfeld schieben. Dort kann der Roboter einzig und allein prüfen, ob er auf einem Hindernis oder auf dem Gold steht. Er hat darüber hinaus kein Wissen, in welcher Richtung das Gold liegt und welcher Weg optimal ist.
Nun könnte man auf die Idee kommen, komplizierte Algorithmen zu entwickeln, z. B.: „Bewege dich vor. Falls Hindernis auftaucht, gehe zurück, gehe links, gehe vor, gehe rechts …“, „Falls währenddessen wieder ein Hindernis auftaucht, gehe nochmal zurück, dann rechts ...“, „Wiederhole das Ganze so lange, bis ...“ usw. Das wird aber schnell sehr kompliziert, wenn man das für jede Startsituation erfolgreich bewerkstelligen möchte. Was wäre z. B., wenn das Spielfeld größer wird oder wenn das Spielfeld gar keine Grenzen hat oder sich das Spielfeld in verschiedenen Leveln ändert? Ebenso wäre es eigentlich kaum möglich, für jedes Startfeld den optimalen Weg zu speichern und diese Sammlung an Wegen zu speichern – zumindest wenn wir das Beispiel auf die reale Welt übertragen, in der Spielfelder nicht 5x5 Felder haben, sondern deutlich größer sind.
Um den letzten Gedankengang zu untermauern, solltest du die nächsten beiden Beispiele absolvieren.
Manuelles Steuern (3)
Betrachte die folgende Situation, in der sich das Spielfeld geändert hat, und überlege dir, welche Schritte des Roboters nun nötig wären, um ihn zum Ziel zu führen.

Benutze insgesamt fünf Pfeile für deine Lösung. Du wirst folgende Pfeile zum Teil mehrfach benötigen: unten, links.
Hinweis: Es gibt mehrere Möglichkeiten.
Es gibt drei Möglichkeiten, das Gold mit fünf Schritten zu erreichen. Eine Lösung davon ist:

Die weiteren Lösungen sind:
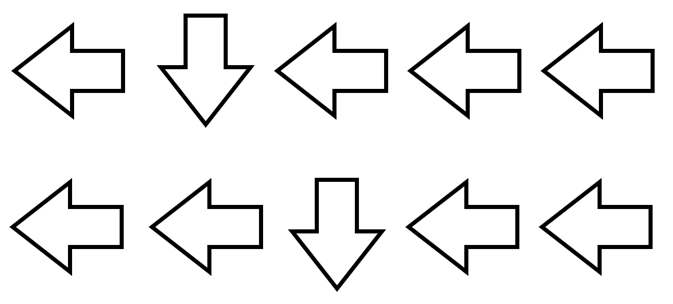
Manuelles Steuern (4)
Betrachte abschließend die letzte dargestellte Situation. Die Welt ist größer geworden. Und wenn der Roboter (oder die Programmierer*innen, die ihn programmieren) keine Kenntnis davon hat, wie groß die Welt ist, kann man diese auch nicht Zeile für Zeile vom Roboter ablaufen lassen. Kurzum: Das Bild deutet es schon an, dass die Goldsuche sehr schnell sehr kompliziert werden kann. Vielleicht schaffst du es trotzdem, den optimalen Weg für diese Situation zu erkennen?

Benutze insgesamt zehn Pfeile. Hinweis: Es gibt mehrere Möglichkeiten.
Eine von mehreren Möglichkeiten wäre:

Fazit zum manuellen Steuern
Es ist ziemlich schwierig, einen allgemeingültigen Handlungsablauf für den Roboter zu erstellen, der immer funktioniert und den Roboter zielsicher zum Gold führt. In der Informatik nennt man einen solchen Handlungsablauf Algorithmus, und in einer Programmiersprache werden nicht nur Anweisungen wie die Pfeile zum Bewegen des Roboters gegeben, sondern auch Entscheidungsanweisungen (um verschiedene Fälle unterscheiden zu können) und Wiederholungsanweisungen (um bestimmte Aktionen mehrfach wiederholen zu können). Aber auch mit diesen Hilfsmitteln ist es sehr kompliziert und aufwändig, eine erfolgreiche Strategie zu programmieren, die fehlerfrei für alle möglichen Situationen funktioniert. Besser wäre es doch, wenn der Roboter von alleine lernen könnte, was der richtige Weg ist! Dies führt uns direkt zum bestärkenden Lernen.
Diese Seite teilen

